What is the NBA equivalent of the "tall cornerback"?
Finding market inefficiencies in the NBA
If you follow the NFL, you are probably aware that the Seattle Seahawks have recently changed the way the game is played. The Legion of Boom (LOB) as we like to call them here in Seattle is filled with stars who were once overlooked in their respective draft classes. The LOB is full of players who didn't fit the prototypical mold for defensive backs which previously existed in the NFL. Pete Carroll and John Schneider saw value in players like Richard Sherman when no one else did. The Hawks loaded up on tall cornerbacks when everyone else was so focused solely on speed. During recent NFL drafts the Seahawks let other teams reach on defensive backs who had attributes like exceptional speed in the first in second round while they sat back and picked up guys like the self proclaimed "best corner in the game" in Sherman and fellow pro bowler Kam Chancellor. Both of these guys they got in the 5th round. These players were overlooked because they were taller than most everyone who played their positions which was looked at as a negative. Then in the 2012 draft the Seahawks managed to do this yet again when they picked up their 5'11" franchise QB in Russell Wilson in the 3rd round. Meanwhile other teams were drafting taller QB's much earlier who they believed fit the prototypical Peyton Manning QB mold. These are a couple big time examples of how the Seattle Seahawks have found market inefficiencies in the NFL and then exploited them to their advantage. Instead of trend-following by overpaying certain types of free agents or reaching in the draft on desirable attributes like "speed" or the "prototypical height/weight for a position" the Seahawks have become the trend-setters of the NFL. This has resulted in resounding success as shown by their recent 2014 Super Bowl championship. I am wondering if the same kind of opportunities can be had in the NBA if teams look hard enough…
To test this idea I thought it would be an interesting experiment to analyze my NBA draft models to see if there are any trends out there waiting to be exploited like the Seahawks have been doing. I looked for these trends from a few different angles which I will go over now.
Comparing meaningful attributes models which predict: draft pick number vs. long-term value
One way I saw to try to find market inefficiencies in the draft is to try to compare what is meaningful from two different models: one model which is optimized for long term value, and another which is trying to predict what draft position a player will go. In theory the attributes which are more heavily weighted in the "predict draft pick" model compared to the "predict long term value" model are the attributes which NBA teams are overvaluing. Similarly you can look at the reverse to find attributes which teams are undervaluing. That is exactly what I have done below.
To do this I generated two different models: one which was trying to predict PER PercentOfDraft (long-term value) and another which was trying to predict which position a player would be drafted (NBA team predicted value). I decided to use a linear model so that I could interpret the model based on the weighting of the attributes. Note that I had to first normalize the attributes in order to be able to interpret the weightings in a meaningful way (or else something like shooting percentage which is always less than 1 wouldn't really compare to something like points per game which would be a much larger number). In addition, the attributes I am using have a lot of correlation between each other so I had to find a way to avoid one model saying "true shooting percentage" is meaningful but "FG percentage" is not and the other vice versa and having to try to interpret this. To avoid this problem I first ran attribute selection on all my attributes before fully building linear weightings. Note that the attribute selection is optimized for the variable we are trying to predict.
I will point out that this whole article is going off the assumption that NBA teams are optimizing their draft picks on long term value when in theory they could be optimizing for something different entirely (star potential, player popularity, players who fit their system, etc).
Below are the rank of most meaningful attributes (ones with the highest linear weighting) for the model trying to predict long-term value (this didn't include draft pick as an attribute) as well as draft pick number.
Long-term value attributes:
- age (negative correlation)
- twoPP
- ts
- team_advanced_efg (negative correlation)
- stl
- team_advanced_ts
- efg (negative correlation)
- dws
- team_fg_percent
- hand_length (negative correlation)
- team_advanced_wl
- team_advanced_ftfga (negative correlation)
NBA team predicted value attributes:
- age (negative correlation)
- fg_made
- dws
- team_advanced_efg
- team_advanced_ftr
- sprint (negative correlation)
- team_fg_percent (negative correlation)
- ts
- team_advanced_wl
- threeP
- team_advanced_ftfga
- team_col_3p_percent (negative correlation)
- team_advanced_ts (negative correlation)
Based on above, here are the attributes which show up as important for predicting long-term value but which don't seem important to NBA teams when considering when to draft a player (in order of importance):
- twoPP
- stl
- efg (negative correlation)
- hand_length (negative correlation)
Here are the attributes which show up as important to NBA teams but not when predicting long-term value:
- fg_made
- team_advanced_ftr
- sprint (negative correlation)
- threeP
- team_col_3p_percent (negative correlation)
These showed up in both models but had inverse correlation between the two:
- team_advanced_efg (value model says negative, NBA team model says positive)
- team_advanced_ftfga (value model says negative, NBA team model says positive)
- team_fg_percent (value model says positive, NBA team model says negative)
I will assume all of these team percentages which are inversely correlated will cancel each other out and I won’t consider them as important.
Observations: - Two point percentage have a strong correlation with fg made but my takeaway here is that NBA teams care more about scoring and less about high percentages - The numbers like guys with lots of steals - The numbers doesn't care for guys who shoot 3's (EFG is essentially FG% but adjusted for 3's) whereas NBA teams prefer guys who can shoot the 3 - The numbers don't like players with large hands whereas NBA teams don’t like slow guys (in terms of sprint speed) - NBA teams like teams with a high free throw rate (i.e. players who get to the line) whereas the numbers don't care
Meaningful attributes in a model which predicts long-term value while having draft pick as an attribute
This is all interesting but lets try to analyze this from a different angle and see if we get similar results. In my original blog post (link) I found that the most successful models were ones built with draft pick number of a player included. This was showing that these models are better at adding meaning on top of scouts/analysts opinions. The scouts insight is very valuable but the model is able to adjust for some key data points the scouts are overlooking. To see what things the scouts seem to be overlooking, we can look at what attributes are important in the models which know about draft pick. Using the same process as above but this time with draft pick included in the long-term success optimized model I found the weighted attributes to be:
- pk (negative correlation - because lower picks is better)
- stl
- age (negative correlation)
- ws
- ast
- twoPP
- numCollegeYears (negative correlation)
- ts
- team_advanced_trb
- efg (negative correlation)
- hand_length (negative correlation)
- threeP (negative correlation)
- pf (negative correlation)
Analysis:
- As expected draft pick number was the #1 indicator and the rest of the attributes are adding meaning on top of that number
- Based on the previous results I am not surprised that steals showed up second on this list
- It looks like NBA teams are over punishing players for age and experience (yes CJ!). This could also relate to my point that the teams might be more interested in "potential" and are willing to take the risk even if it doesn't pan out over a more likely to succeed 4 year college player.
- NBA teams aren't taking into account an advanced stat like win shares enough it seems - I wonder if this has changed over the years? Look for a future post looking at if these trends are changing over the years.
- The numbers seem to like assists more than NBA teams
- Once again two point percentage shows up in addition to true shooting percentage as something the NBA teams are overlooking a bit
- team_advanced_trb represents total rebound percentage - this is an attribute which I have seen time and time again when looking at the models which know about draft pick. I think there is something hidden here about players who play for teams who get a higher percentage of rebounds. I think this could translate to good spacing, anticipation, and basketball IQ. I want to deep dive this one more at some point.
- Similar to above, the signs are pointing towards NBA teams overvaluing 3's (efg, threeP)
- As discussed in a prior post hand_length shows up as a negative indicator here as well
- Last but not least, personal fouls seems to have a negative correlation with success, I'm not sure how meaningful this is since it is the lowest weighted attribute but it is interesting nonetheless. Is it possible that guys who are prone to fouling in college play are also prone to fouling out in the NBA and are therefore less successful because of less minutes? Sounds like an interesting study.
Building a model which predicts draft pick overachievers
A third method I wanted to pursue to try to look for inefficiencies was to build a model which optimizes for players who overachieve and see what it valued. Conceptually each draft pick has some value associated with it. Over the years certain kinds of players have outperformed this value while others have underperformed. If we could put a number on what that value is for a draft pick we could build a model which tried to predict value relative to the players draft pick and see which kinds of players are likely to overachieve.
To build such a model I first need to understand what the value of each particular draft pick is. To do this I plotted all players PER Percent of Draft value along with their draft pick number. Then I built a best fit logarithmic line to come up with a formula which estimates expected value for each draft pick number. Here is a graph showing this:
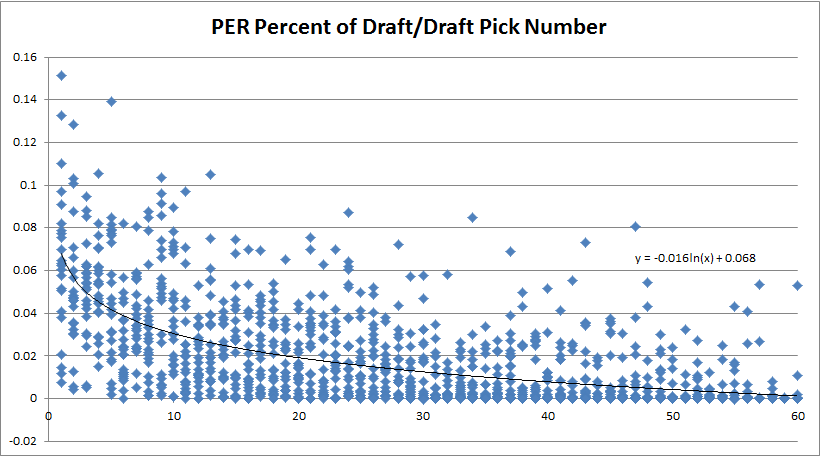
This ended up generating a formula of: perPercentOfDraft = -0.016ln(draftPickNum) + 0.068
Now that I have expected value for each draft pick I can subtract this value from a player’s actual value historically and build a model on what value they have left (i.e. how much they overachieved). Their "value" would then instead represent: how much their long-term value overachieved compared to their draft pick number. Note that if they underachieved this value would be negative. Using this method I created a model and analyzed the most important attributes as previous sections:
- stl
- age (negative correlation)
- team_advanced_ftr (negative correlation)
- team_advanced_ftfga
- twoPP
- team_col_3p_percent (negative correlation)
- team_advanced_wl
- threeP
- ws40
- team_ft_percent
- hand_length (negative correlation)
- ftp
It looks like a lot of the same things show up here are previous sections. Steals is at the top again, this sounds meaningful!
In the future I would like to run some cross validation on this to see if this kind of model is at all accurate at predicting overachievers and if so then I would like to see what it thinks about 2014 draftees.
What other ways can NBA teams find and exploit market inefficiencies?
This kind of research isn't just limited to draft day, for example it should be possible to learn models for other concepts such as: what kinds of free agents are overlooked and/or underpaid. Another huge win could be finding ways to integrate market inefficiencies more closely with the a team's strategy.
One way this could be done is to adopt the organization's playing style to take advantage of the inefficiency. An extreme example of this might be if it were found that short quick point guards were an undervalued commodity and then this triggered the team to adopt their playing style to play 5 point guards at once. They may end up coming with a new revolutionary type of system around this and the reason it worked is because they could get so many talented quick point guards for cheap because they were undervalued.
Another way teams could use this kind of mentality to their advantage would be to find the inefficiencies which relate to the their particular playing style. For example lets consider a scenario where a team’s coach is very set on the type of defense he wants to run - he might insist that the defense must be high pressure at all times. Then it would be useful to do similar research to find out which kinds of players are overlooked but which can play pressure defense all game long. Maybe guys who play lots of MPG in college tend to have better conditioning and are able to play pressure defense more consistently? Maybe there is a subset of those players who didn't show other signs of "long-term value" but which showed strong signs of being able to play pressure defense - the team could take advantage of these otherwise underutilized set of players because they would be perfect for the team’s system?
There are lots of opportunities to be had here. The game will change because of it. Teams will adopt and trends will reverse. Teams can't wait for other teams to show them what the trends are or it will be too late. Instead, teams need to be at the head of the pack, being the trendsetter themselves…like my forward thinking local football team…Go Hawks!
Future posts:
- How have market inefficiencies changed over the years?
- How well does the “predict overachieve model work”?
- Which 2014 draftees are most impacted by these market inefficiencies?